Why you should be testing your 404 pages web performance
So some recent web performance monitoring work for GOV.UK piqued my interest in the web performance of 404 pages. In this post I'm going to go into some of my thoughts around this and the finer details of existing 404 pages on the web today.
Anatomy of a 404 page
So before I start, let's get the basics out of the way. What is a 404? Well I'd hazard a guess that the 404 status code is the most well known of all the HTTP status codes. If you were to ask a random person on the street what a 404 is, I'd bet many could guess as to what it is. Maybe something along the lines of "it's when the website is broken", or "the page is broken".
Let's take a look at what the Internet Engineering Task Force (IETF) RFC 7231 has to say about the 404 status code
The 404 (Not Found) status code indicates that the origin server did not find a current representation for the target resource or is not willing to disclose that one exists.
So saying the website or page is broken is close, but it isn't always about 'pages', as the rfc mentions the word 'resource'. The user will most likely see a 404 as a broken page. A browser on the other hand could be seeing 404's for a huge number of reasons, and in many cases a user won't even realise this. I can't stress this point enough: 404 responses aren't just caused by a user mistyping a URL, there's a whole lot more to it than that. I'll back this claim up with data later in the post.
What decides what is sent in a 404 response
When a browser requests a resource from the server, and the server doesn't have it available, what decides what is sent back to the browser? Well multiple representations of a resource can sit on the same URL. The process for selecting which resource is the best representation to be used and sent back to the browser is called content negotiation. The MDN documentation explains it well. The key part is:
The server uses [HTTP headers] as hints and an internal algorithm chooses the best content to serve to the client. The algorithm is server-specific and not defined in the standard.
So the browser gives the server as much information as it can about the type of content it supports and what it is expecting (as a hint), then it is the decision of the particular server's algorithm exactly what is in the response. And this is where the selection happens. It then depends on how the server is configured as to if a custom error page is served (e.g. site branding, more natural languages, site CSS and JS), or if the servers default '404 Not Found page' is used.
Collecting and refining the data
In terms of 404 status data, thankfully there's an awesome project that has been running for a number of years called the HTTP Archive, which tracks how the web is built. Every month, millions of URLs are 'crawled' and a huge amount of data is captured and stored that can then be used by the web community to learn about the state of the web today, and how it is changing over time. This data just so happens to include error data too! So we can take a look at the current state of 404 pages across the web in great detail.
Using a fairly straightforward SQL query we can pull out the response body size of all the 404 pages in the HTTPArchive as of June 2020:
#standardSQL
select status, respBodySize, reqBodySize, url
from httparchive.summary_requests.2020_06_01_mobile
where status = 404
order by respBodySize desc
Big thank you for Andy Davies for the query and pulling the data from the archive. Just to give you an idea of how much data comes back: it gives you a CSV file containing 3,382,962 rows, and is around 290MB uncompressed! Given the maximum file size for a CSV in Google Sheets is 20MB, and there is a cell limit of 5 million cells, we're going to need to reduce the amount of data by a lot at some point in this post!
Full dataset breakdown
Before I refine the dataset to make it more manageable, let's gather some high-level information about where all these 404 errors are coming from. First thing to do is to de-duplicate the data, making sure any repeated URLs are removed. For many sites you're going to get the same 404 repeated across multiple pages. Doing this removes 443,080 rows from the CSV, so not a bad start! You can find a Google Sheet with my basic analysis of the full dataset if you'd prefer to view it there.
First let's see the file types that are missing which are causing the 404 errors:
| Filetype | Number of occurrences | % of total |
|---|---|---|
| *.ico | 639,344 | 21.75 |
| *.jpg | 618,335 | 21.03 |
| *.png | 526,360 | 17.90 |
| *.js | 298,193 | 10.14 |
| *.css | 148,884 | 5.06 |
| *.gif | 144,576 | 4.92 |
| *.woff2 | 54,758 | 1.86 |
| *.woff | 53,202 | 1.81 |
Unsurprisingly image files are the main cause of 404 errors. But the top filetype is *.ico. Any guesses as to why this is? Winner gets the prize of one lovely favicon.ico to download.
What about if we look for common files in these 404 errors:
| Filename | Number of occurrences | % of total |
|---|---|---|
| favicon.ico | 632,384 | 21.51 |
| ajax-loader.gif | 19,855 | 0.68 |
| favicon.png | 18,247 | 0.62 |
| manifest.json | 11,411 | 0.39 |
| site.webmanifest | 4,783 | 0.16 |
| sw.js | 1,859 | 0.06 |
| spacer.gif | 1,375 | 0.05 |
| Favicon.ico | 295 | 0.01 |
So I think we've confirmed the answer as to why the *.ico filetype has such a large number of occurrences. That's 21.51% of the unique URLs listed in the full dataset are caused by missing favicons!
Finally let's look for common URL patterns that are causing 404 errors. These are just a few that I pulled out that I found quite interesting:
| URL Pattern | Number of occurrences | % of total |
|---|---|---|
| "/wp-content/uploads/" | 375,123 | 12.76 |
| "/wp-content/themes/" | 136,303 | 4.64 |
| "apis.google.com" | 71,264 | 2.42 |
| "/wp-content/plugins/" | 65,967 | 2.24 |
| "cdn.shopify.com" | 42,871 | 1.46 |
| "fontawesome-webfont" | 33,916 | 1.15 |
| "/undefined" | 22,482 | 0.76 |
| "/null" | 9,540 | 0.32 |
| ".gov.uk" | 971 | 0.03 |
| ".nhs.uk" | 551 | 0.02 |
| "/Array" | 470 | 0.02 |
| "[object%20Object]" | 292 | 0.01 |
| "/NaN" | 153 | 0.01 |
The top two URL patterns are related to WordPress, which to be honest isn't very surprising, considering according to the 2019 Web Almanac the most popular CMS (by far) is WordPress.
Refined dataset breakdown
So the full dataset with 3,382,962 rows is far too big to manipulate and analyse (for me using Google Sheets), so moving forwards I decided to reduce the original dataset by:
- removing any URLs with a response body size of less that 100KB
- again de-duplicated the remaining urls to make sure they were unique
This reduced 3,382,962 rows down to a much more manageable 11,621 rows. Why 100KB? Good question. It just seemed like a fairly round number which gave a suitably large number of results remaining. I personnel think 100KB for a 404 page is still quite large (but much more on this later). If you are interested in the resulting raw data, you can find the Google Sheet here.
NOTE: For readers curious about how to access HTTPArchive data, I highly recommend reading 'Getting Started Accessing the HTTP Archive with BigQuery' written by Paul Calvano, and 'Using BigQuery without breaking the bank' by Tim Kadlec.
So for the top 11,621 URLs (in terms of response size) that were 404 errors, what file types are missing that are causing the errors:
| Filetype | Number of occurrences | % of total |
|---|---|---|
| *.png | 2,201 | 18.94 |
| *.jpg | 2,120 | 18.24 |
| *.js | 1,962 | 16.88 |
| *.ico | 1,836 | 15.80 |
| *.css | 533 | 4.59 |
| *.gif | 392 | 3.37 |
| *.json | 348 | 2.99 |
| *.woff | 285 | 2.45 |
Icon files are no longer top of the list in the refined dataset, but images and scripts are.
What about if we again look for patterns in common files causing these 404 errors:
| Filename | Number of occurrences | % of total |
|---|---|---|
| favicon.ico | 1,757 | 15.12 |
| manifest.json | 259 | 2.23 |
| favicon.png | 230 | 1.98 |
| site.webmanifest | 112 | 0.96 |
| ajax-loader.gif | 94 | 0.81 |
| serviceworker.js | 12 | 0.10 |
| sw.js | 8 | 0.07 |
| Favicon.ico | 7 | 0.06 |
| manifest.webmanifest | 7 | 0.06 |
| spacer.gif | 0 | 0.00 |
So even in our refined dataset the favicon.ico file creates real problems!
Finally what about common URL patterns causing the 404 errors:
| URL Pattern | Number of occurrences | % of total |
|---|---|---|
| "/wp-content/uploads/" | 2,284 | 19.65 |
| "/wp-content/themes/" | 1,294 | 11.14 |
| "/wp-content/plugins/" | 1,116 | 9.60 |
| "/undefined" | 255 | 2.19 |
| "fontawesome-webfont" | 166 | 1.43 |
| "/null" | 33 | 0.28 |
| "/Array" | 23 | 0.20 |
| ".gov.uk" | 2 | 0.02 |
| "apis.google.com" | 0 | 0.00 |
| "cdn.shopify.com" | 0 | 0.00 |
| ".nhs.uk" | 0 | 0.00 |
| "[object%20Object]" | 0 | 0.00 |
| "/NaN" | 0 | 0.00 |
Again, the top entries are all related to the WordPress CMS. A Google Sheet with my basic analysis of the refined dataset can be found here.
Response sizes
A really important aspect of these 404 responses I've only briefly touched on so far (other than the 100KB limit) is the actual response body size that is being sent to a clients browser. When a user visits a site's 404 page, either directly or unseen via the browser requesting a resource that doesn't exist on the server, the server is going to respond with a 404 status code and the associated 404 page. Looking at the refined dataset gives you some pretty staggering examples of 404 response bodies that are quite frankly huge. There are 118 examples of 404 pages that are 1MB+. 17 examples where the response body size is 2MB+. And the award for the largest 404 response body size is a whopping 6.7MB!
Huge 404 page waterfall
So what does a WebPageTest waterfall chart look like for one of these sites that has a huge 404 page response? I've picked the 2nd largest on the list for the moment as it is a very basic direct example. I will examine the first place website later in the post, as it comes with quite a few quirks! To force WebPageTest to run a test on a 404 page I've had to follow the instructions I have written here, as if you don't WebPageTest will simply abort the test (it is giving a 404 error response after all, so it's to be expected).
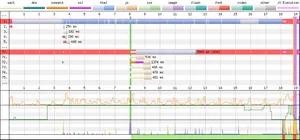
In this particular instance the HTML makes up 85.4% of the total page weight, or 7.5MB on its own! This looks to be mainly inline CSS within the page. After forcing the test to run for 20 seconds the page still hadn't fully loaded. My guess is that there's some broken server code or a plug-in that has gone off the rails and is injecting all this CSS multiple times and increasing the page weight by megabytes! The fact that I forced the test to run for so long, and it had only just finished loading suggests to me that the size logged in the HTTP Archive data is actually smaller than it should be!
That is one huge 404 page! And given that this is a page that ultimately a user doesn't actually want to be on, that's a lot of wasted time, data, and device resources!
Examining the breakdowns
Now that we have the broken down what is causing the 404 error data, what conclusions can be drawn from it?
Favicons
21.5% of the unique URLs in the complete data set came from a missing favicon.ico. Refining the data down to the top 11,621 URLs with the largest response bodies reveals that 1757 (or 15.1%) URLs on that list show the same issue. It just so happens that the largest 404 page in the whole data set is being triggered because of a missing favicon.ico on the server. By default a browser automatically looks for the favicon.ico in the websites root directory (if a <link rel="icon"> isn't present). If no icon is found, a server will respond with a 404 page. In the case of the largest 404 page a 6.7MB response from the server is sent to the client. This is on top of any data actually needed by the browser to render the page! All the time this is happening the user has no idea. It's not like they see a broken image. The page is just incredibly slow to load. And to top it all off this happens for every page on the site (as the browser is still looking for that elusive favicon.ico it wants).
You can see this happening via a WebPageTest waterfall on a cable connection using Firefox. And yes, you are reading that correct, 17.3 seconds to load the 404 response, amounting to 44 seconds for the full page load!

The impact of missing favicons on web performance has been written about before, and under certain conditions can cause you hours of debugging. So do yourself and your users a favour, as a bare minimum stick the most basic favicon.ico at your server root.
Wordpress requests
The "/wp-content/uploads/" URLs are understandable in many cases. A content author uploads an image, maybe modifies the post or the image is renamed / deleted from the server, thus creating the 404 error.
It's the "/wp-content/themes/" and "/wp-content/plugins/" URLs that really worry me. WordPress has an excellent upgrade mechanism for both plugins and themes: simply click a button and it does it all for you. Great! But what you are essentially doing is then trusting that the developers of every plugin and theme you use on your site aren't now injecting a broken resource link into your pages! If they do, you aren't likely to notice it unless you check the browser console, it breaks functionality in some way, or you happen to be monitoring your server logs for 404 responses. But when that broken resource is injected into every page, and a 404 status code and page is sent, that's when it could effect web performance. And as you can see from both sets of data this isn't a rare occurrence, it is happening a lot for WordPress sites!
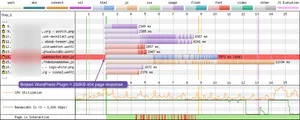
In the above example we see a page trying to load a broken WordPress plugin called WaveSurfer-WP, only the JavaScript file is missing causing the browser to download an additional 288KB!
JavaScript
Both datasets show a high percentage of broken JavaScript requests that are generating 404 errors. But it's actually worse than that. At least if a whole JavaScript file fails to load you are likely to notice it. But what about if you are using JavaScript to generate URLs for a particular component on your site. It then downloads assets from your server in a very Ajax fashion, but the JavaScript doing this fails in some way. This isn't hypothetical, we can actually see it happening in the HTTP Archive data in these URL patterns:
- "/undefined"
- "/null"
- "/Array"
- "/NaN"
- "[object%20Object]"
These are all URLs being generated using JavaScript which are failing for some reason. And in doing so they are making a request to the server for a resource that doesn't exist. At which point the server responds with a 404 status and the corresponding page page. So unless you have a rigorous set of tests to catch these edge cases in your JavaScript, these 404's could be occurring and you'd have very little knowledge of them happening. The user certainly isn't likely to check their browser console, so unless it breaks the site completely, they may not even know it is happening.

In the above example we see some broken JavaScript requesting a resource from '/undefined', and the browser receives a 294KB response back.
Standard files
Outside of the usual favicon.ico file, a whole range of files appear in many of the 404's logged, and they are all manually inserted by developers:
- "favicon.png"
- "ajax-loader.gif"
- "manifest.json"
- "site.webmanifest"
- "manifest.webmanifest"
- "sw.js"
- "serviceworker.js"
Proving mistakes do happen. Even though a developer has added the <link rel="manifest" href="/manifest.webmanifest"> to the <head>, the actual manifest file has been forgotten about. Or maybe it was added but then deleted in a future release by mistake. Who knows. Again in both instances causing a 404 response on all pages it sits on (maybe all of them!).

In the above example the favicon.png file doesn't exist on the server, so it returns a 285KB 404 page. But it also sends the page with a 200 response code, with a 404 response body. This is known as a 'soft 404', and can be the result of incorrectly configured server software.
Presentational assets
I was actually quite surprised at how many CSS and font files (WOFF2, WOFF, TTF) were causing 404 errors in the datasets. Of all the assets that are likely to display presentational issues (and therefore likely be noticeable to both developers and users alike), these would be it. But it could be that these CSS and font files are only being used for particular pages or site components, so maybe hidden away in depths of the site. Or if you have a good CSS font stack configured, the use of a web font may not always be noticeable (which begs the question why load it in the first place). In any event, these filetypes appear a huge number of times across the full dataset, so it's quite a common occurrence.
In the example below a missing CSS file triggers a 270KB 404 page response:

Ultimately with each of the five examples of potential causes of 404's listed above, there's a chance that an unoptimised 404 response will cost the user dearly, both in terms of web performance and also device resource and data usage.
What about testing?
So here's the thing about synthetic monitoring and automated performance testing of 404 pages: it's actually almost impossible to do with many services at the moment (if you know of any, please let me know). The reason being is that many synthetic performance testing tools are built upon either Google Lighthouse or WebPageTest. As an example, let's see what happens with these tools if we try to audit a 404 page:
Lighthouse
Running a Lighthouse audit on a 404 page causes the tool to abort the process with no data being captured about the page. This is fully understandable really, it is an error page after all! But it's a shame there isn't an option to override this implementation detail and force the collection of data if a 404 status code is encountered.
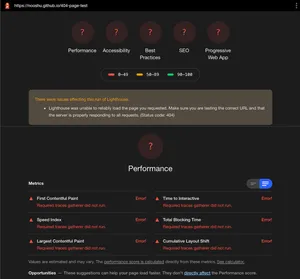
WebPageTest
This is the default setup for WebPageTest, and the waterfall that is generated if you point it at a 404 page. Now there is a way to force WebPageTest to capture data from a page when it encounters a 404 status code. It's a bit of a hack but it does work.

Browser DevTools
Your best bet for examining the asset sizes for your 404 pages at the moment is to resort to your browser developer tools. Take a look in the network tab and see what is being loaded, and approximately how long it is taking. You could even try throttling your network connection to observe just how long it takes for the 404 page to be loaded and rendered.
404 Caching
Using the browser developer tools it is possible examine and optimise the caching strategy used on your 404 page. There's two types of caching to consider when it comes to 404 pages: CDN cache and local browser cache.
CDN cache
The thing about hitting a 404 page is that there's a high possibility that this request is going to be sent straight to your origin server. But if you place a CDN in front of your origin, you have the chance to cache the 404 page response on the CDN. This is a good idea since without it, hitting a 404 page could be used as a DoS attack vector, by forcing the origin server to respond to every 404 request rather than letting the CDN respond with a cached version.
Check the documentation for your specific CDN to see how they handle caching of 404 pages by default, as each CDN has their own strategy for caching 4xx status codes received from an origin server.
Local browser cache
Should a browser cache the HTML page and assets when it encounters a 404 page? Caching and cache correctness related to 4xx responses is actually specifically mentioned in rfc 2616 - Hypertext Transfer Protocol -- HTTP/1.1:
A correct cache MUST respond to a request with the most up-to-date response held by the cache that is appropriate to the request which meets [one of] the following conditions: It is an appropriate 304 (Not Modified), 305 (Proxy Redirect), or error (4xx or 5xx) response message.
So there's nothing technically stopping you from setting Cache-Control headers for your 404 page and associated assets and requesting that a browser cache them.
Design considerations and caching
Now you may be asking: why on earth would I want to cache 404 page assets? Most users will likely visit a 404 page and then immediately hit the browser back button.
That will be true in many cases, but think about it this way: the assets have already been downloaded so why not request to cache them. Then if you can offer a user an easy way to get to the rest of your site (e.g. homepage link, search functionality, popular articles call to action), the 404 page could actually be used to warm the cache for the rest of the site visit. This initial failure could be converted into a web performance win, should a user decide to explore the rest of the site.
Users encountering your 404 page should be factored into your user journey planning, because at some point they are going to see it. So take the time to consider how users can recover from their mistake (or the mistake of another person e.g. mistyping a URL in a blog post).
Possible solutions
So there are a couple of possible solutions to help fix issues with 404 pages on your site:
Favicon and monitoring
First is make sure you have a favicon.ico file at the web root of your server. It doesn't even need to be of anything, it could simply be transparent. Just as long as it is present and the server can serve it if it is requested. Next step is setup monitoring so you can see where 404's are occurring on your site so they can be fixed. This can be done using a variety of methods, from Web log analysis to the Google Search Console.
Correct server setup
But you could take it further. Ideally you only want to be serving HTML to the browser when it expects a HTML response. And for all other responses serve a small error payload. How this is setup depends on the web server or CDN being used. Listed below are example configs for NGINX and Apache, where as a default we are setting the custom error page, then for specific locations we are serving the small 404 response (assuming the files don't exist).
# NGINX
location ~* \.(ico|jpg|jpeg|png|gif|svg|js|css|swf|eot|ttf|otf|woff|woff2)$ {
error_page 404 /small_404_response.txt;
}
error_page 404 /custom_404.html;
# ApacheConf
<Location ~ "(\.ico|\.jpg|\.jpeg|\.png|\.gif|\.svg|\.js|\.css|\.swf|\.eot|\.ttf|\.otf|\.woff|\.woff2)$">
ErrorDocument 404 "404 Not Found"
</Location>
ErrorDocument 404 /custom_404_page.htmlYou can complete the same task using various different methods in Apache and NGINX, the above is just one example.
You can actually see this in action by looking at how Facebook has their servers setup.
Here we aren't matching against a particular location (e.g. https://www.facebook.com/test.). Because of this a full HTML response is being served:

But if we request a location that matches a particular file extension (e.g. https://www.facebook.com/test.jpg) the 404 response is much smaller:

A 72 byte response saying 'Not Found' then a link back to Facebook.
Conclusion
Assuming that an optimised 404 page is only required because users will mistype a URL in their browser is short-sighted. As the HTTP Archive data has shown, there are many other reasons why a user may encounter a 404 response (even if they have no idea they actually are!). The web performance impact of a users browser loading an unoptimised 404 page can be huge, and it can have a real impact on their experience of your whole site. All it takes is a forgotten file or misplaced ; in some JavaScript, and your users could be encountering it.
Automated web performance monitoring of 404 pages is very difficult at the moment, as most tools don't capture data when encountering a 404 status code. So it's likely you will need to check your 404 page manually using a browsers developer tools. I'd love to see this change in the future and see tools implement some form of '404 mode' for testing 404 pages. It's really important that users aren't penalised for a mistake (either theirs or that of another person).
So why not check the state of your sites 404 page right now? Check your server logs so spot where 404's are happening across your site. Because I guarantee at some point a user is going to encounter one, even if they don't realise it.
June 2024 update
As of October 2023 this functionality was available in Lighthouse by using the ignoreStatusCode option. And as of the 5th June this is also available in PageSpeed Insights. See a sample 404 report here. For more information on this change see issue 10493 in the Google Chrome Lighthouse GitHub repository. Many thanks to Paul Irish and the whole of the Google Lighthouse team for adding this feature!
Post changelog:
- 25/08/20: Initial post published.
- 26/08/20: Minor adjustments / clarifications, thanks Barry Pollard. This is why you always get someone else to proofread before publishing!
- 27/08/20: Added information about 'soft 404s' and the 'What decides what is sent in a 404 response' section. Horizontal scrolling of wide tables is now possible across the whole site (Thanks to Ed Horsford for reporting)
- 28/08/20: Added a section about possible solutions related to 404 page monitoring, and serving a smaller response depending on the location the client requests. Thanks Barry Pollard and Paul Calvano for the feedback.
- 07/07/24: Added an update from Paul Irish about support for 404's in Lighthouse and PageSpeed Insights. Thanks Paul!