A 'Vary' unusual waterfall
So as I've mentioned a few times before on this blog, we (GDS) use SpeedCurve for our synthetic web performance monitoring. We've been using it for a while, but in a very ad-hoc fashion. Recently I finally got round to setting up a whole set of monitoring on our services to let us know when things change (both positive and negative). So back in April an alert appeared for one of our services: GOV.UK Notify. Seemingly overnight without warning the font size in Chrome jumped from 157KB, to 331KB. That's a whopping 110% increase!
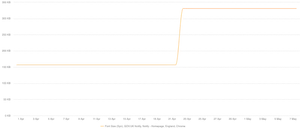
Checking in with the team, nothing had changed with the code that could cause this for quite some time. Delving into the details a little further we could see that the number of font requests had jumped from 5 before, to 8 after. Very unusual considering no code had changed to trigger it.
The waterfall
One of the great features about SpeedCurve is the ability to jump directly into the underlying test data, since it is all powered by WebPageTest, it's a tool I'm a little more familiar with. But the waterfall I was presented with was one I'd never seen before:

On first sight the browser is requesting both WOFF2 and WOFF fonts at the same time. Looking a little closer requests 6 and 7 are very strange. Both are requests by the browser for the WOFF2 fonts. On examination you can see the server attempting to send the browser (Chrome) the font files. This is indicated by the dark red bands (known as chunks). But the strange thing is the independent, unconnected bands. It looked as though the server sends some data, stops for 10-20ms, then tries again. Eventually the sending of data fails, the fonts are not received and the browser moves on.
The fallback WOFF fonts
The intriguing part for me is looking at where the 'fallback' WOFF fonts are requested by the browser:

Notice how just as the browser receives the first WOFF2 font data it immediately initiates the request for the equivalent WOFF fonts. My interpretation of this is that as soon as the browser sees the WOFF2 data, it knows there is an issue and that it can't use the data, so it immediately requests the fallback. This happens for both WOFF2 fonts on the page. Assuming my interpretation is correct, once the WOFF2 files have been requested they will be using up bandwidth, and if the browser can't use the data they will be wasting that bandwidth. By the time the browser cancels the font requests (HTTP/2 only), the fonts may have already arrived (as seen in the waterfall above).
Historic data
Thankfully we'd had SpeedCurve setup on a few Notify URLs for approximately 6 months, so we had a large amount of data to look back on. In examining historic data about the font size, an interesting pattern emerged:
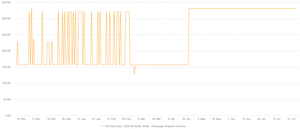
This font size 'change' had happened at least 25 times in the past 6 months, then mysteriously reset itself. It's also possible to see in the data a few 'half jumps', where only one of the WOFF2 font files had the issue, and the other downloaded fine. I concluded from this that it wasn't anything the team were doing, this was something else much more random.
But what really triggered the investigation was that after the 21st April, the font size became permanently stuck (as can be seen to the right of the graph).
More investigation
Chatting to the team further they mentioned something quite intriguing. While developing the site they occasionally ran into seemingly random console errors. They'd pop-up for a single load, then immediately disappear after a refresh, meaning they had no chance to debug the issue or consistently reproduce it to allow them to fix it:
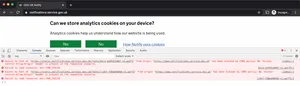
As you can see above, it's a Cross-Origin Resource Sharing (CORS) error related to the Access-Control-Allow-Origin header on both WOFF2 fonts. This gave us the first indication as to what the issue was.
So what changed?
Another great point about SpeedCurve, since it is all built upon WebPageTest, under all the useful graphs you can delve into an incredible amount of information about the page load process. Given that it's possible to look at the point before the issue happened, then the point after it happened, it's possible to compare test results and look for clues. Since it looked to be CORS related the obvious place to look was the response headers for the WOFF2 files. This is what a successful response looked like, and here's the failed response, both for the same file. Just a few initial observations when comparing the headers:
- Both responses came from the same CDN point of presence (PoP):
LHR3-C1. content-lengthand theetagvalues are both exactly the same, so the binary file itself hasn't changed (byte-for-byte identical since a strong ETag validator)- The
date,last-modified, andageheaders have changed. - The failed response is missing all
access-control-*headers.
The access-control-* headers are CORS headers. So CORS rears its ugly head again. The date, last-modified, and age headers indicate that although the file itself may not have changed (in terms of bytes), the surrounding metadata has. And given the last-modified value was now Tue, 21 Apr 2020 14:32:51 GMT, the date our issue appeared, I'd guess they are related!
Caching on a CDN
So GOV.UK Notify hosts all of their static assets on the Amazon CloudFront content delivery network (CDN). In order to minimise latency for users, CDN's will cache requests on their own servers. This takes the load off a website's origin server, and allows a CDN to serve assets to a user from a PoP that is geographically closest to them. This is because lower latency generally equals better web performance. But there's a popular saying in Computer Science:
There are only two hard things in Computer Science: cache invalidation and naming things. -- Phil Karlton
Caching is a difficult problem to solve. Getting something into cache is easy, but making sure that it is still an accurate representation of the original at all times is difficult! So what if that's what has happened here. The version stored in the CDN cache is in some way broken and it is being served to the client, and the client is rejecting it. This actually happens a lot, sometimes by accident, other times used maliciously as a security exploit. This is known as web cache poisoning. The theory being that by injecting compromised code into a CDN's cache, it could then be served up to all users. If you are interested in finding out a lot more about this topic I highly recommend reading 'Practical Web Cache Poisoning' by James Kettle.
Just to be clear, I don't think what happened is malicious in any way, shape, or form. It just highlights that this could be the issue, and gives it a name for further investigation. A quick Google for 'CloudFront no Access-Control headers' very quickly brings you to this incredibly detailed post on Serverfault all about it. Reading through that post quickly leads you to a possible solution: the vary header.
The vary header
So let's briefly chat about the vary header. CDN's use what is called a cache key to check to see if the request being made for a file and the file that already exists in the CDN cache is the file the browser is expecting. For that reason you want your cache key for a particular resource to be unique. That way you can avoid cache collision, where an outdated version of a file is served to a user. Default cache key settings differ depending on the CDN being used, but they can often be customised and configured by a developer. For example, the default cache key could be the complete Uniform Resource Identifier (URI) for a particular request. So say we have a file already cached on a CDN, https://nooshu.github.io/images/fake-image.jpg and we make a request for it using the following URI reference:
- Request for
https://nooshu.github.io/images/fake-image.jpg= match - Request for
http://nooshu.github.io/images/fake-image.jpg= no match (HTTP, not HTTPS) - Request for
/images/fake-image.jpg= no match (Missing scheme and authority) - Request for
https://nooshu.github.io/images/fake-image.jpg?cachebuser=123= no match (URI queries matter)
What the vary header allows you to do is add specific client request headers to also be 'keyed' by the cache. So for example, if you wanted to make sure a CDN is always serving up the correct version of a file depending on its compression type, you would specify vary: Accept-Encoding in the response. The CDN would then examine a future clients Accept-Encoding header to determine which file to serve from its cache. If the client requests uncompressed, it serves an uncompressed version from cache. If the client requests a gzipped version, it gets a gzipped version from cache. If a version being requested doesn't exist in the CDN cache, it will go back to the origin server for a copy (then save it for the next client who requests it).
vary origin
So what is the vary: origin response header doing? It is saying to the client that "when I serve a file to you, I'm taking into account the origin header from which the request is being made from." So for example, if two requests are being made for the same file but the origin header is different for each request, multiple versions of the same file will now exist in the CDN cache. Should another client come along and make the request from the same origin, they get the version of the file associated with that origin only.
Font's (for reasons we won't go into) need the access-control-allow-origin header to be set when loaded as part of a page. This can either be a wildcard, or the request origin reflected back. origin headers are only sent with CORS and POST requests, so the CORS request to the WOFF2 fonts that sit on the GOV.UK Notify assets domain already contains an origin header. So what would happen if we didn't set up the CDN to consider this origin header in the request when caching font files on the CDN? Well the CDN could be serving a version of the font files (including headers) to a client that is missing vital information it needs to use them e.g. missing CORS headers (access-control-*).
So what exactly happened with the CDN cache?
Well that's the million-dollar (pound) question isn't it. And unfortunately why exactly this was happening and what triggering it is still a complete mystery to me. But the theory I'm going with is this:
- something triggered the CDN cache to be cleared, meaning the WOFF2 requests no longer existed in the cache
- A request was made by someone for the WOFF2 fonts that primed the cache with a non-CORS version of the font response e.g. by someone directly navigating to the file (a navigation request is non-CORS)
- Because the the
Originisn't being considered as a cache key (Vary: Origin), this non-CORS version is then served back to the Chrome client without the correctaccess-control-*headers - No CORS headers set on the font response is going to cause issues, leading to the WOFF2 font not being used by Chrome
- The browser immediately requests the fallback WOFF fonts which are then used (assuming they are cached correctly)
- SpeedCurve sees the additional font requests (even though the fonts weren't actually used) and it updates its graphs accordingly
Cache persistence
Another strange thing I noticed was that this issue was easily reproducible on the public instance of WebPageTest. All you needed to do was select the 'London, UK - EC2 - Chrome' instance. But when I selected any other instance it didn't show the issue. I found this interesting because SpeedCurve run their own WebPageTest instances on Amazon EC2. How is it that 2 separate WebPageTest instances on EC2 are displaying the same issue, but other instances are fine. On examining the response headers it is easy to see why:
- SpeedCurve instance (failed response):
x-amz-cf-pop: LHR3-C1 - Public EC2 instance (failed response):
x-amz-cf-pop: LHR3-C1 - Public non-EC2 instance (successful request):
x-amz-cf-pop: LHR61-C2
The two EC2 instances (both in London) were receiving responses from the same CloudFront edge node (LHR3-C1), whereas the other public non-EC2 instance was receiving the request from another edge node (LHR61-C2). And this is what was happening every single day when the test was run. The SpeedCurve instance was hitting the same edge node which had the poisoned cache, hence the reason why the graph was constantly showing the issue. Same Chrome browser, same EC2 instance every day with the same poisoned cache (with long-lived cache headers max-age=315360000, immutable) is going to show the same issue (unless the CDN cache is cleared).
Re-examining the waterfall
Now that we have a bit more of an idea about what is going on, lets re-examine the original waterfall to pinpoint what is happening:

- First the WOFF2 font files are requested by the browser after a new TCP connection is established
- A very thin slither of data is received (most likely the headers)
- The browser immediately cancels the request as there are no required CORS headers. This explains the 'empty space' between the data.
- The browser immediately requests the next fonts in the
@font-facedeclaration (requests 8 & 9) - The browser still receives chunks of WOFF2 data because this data was already in transit over the network or sitting in one of many buffers along the way.
It never ceases to amaze me the amount of information you can get from a waterfall chart once you know what to look for!
Solution
Well after all the discussion above the actual solution is very simple (in theory). Add vary: Origin to the response for the web fonts and purge CloudFront cache on every node. Unfortunately it's not always that simple. Looking at the CloudFront documentation on how it handles vary headers, they have specific rules around what is automatically removed. But it is still possible. Once merged and deployed the issue was fixed:
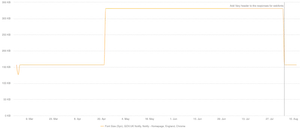
Now admittedly this isn't the most exciting graph ever, but it does show that it immediately fixed the issue, bringing the number of font requests and the total font size down to the correct value after being stuck there for a number of months. And from all the discussion above, this should now have solved the issue for good. No more random CORS errors for Chrome users and potential wasted bytes on fonts that couldn't actually be used.
Learnings
So there are a couple of learnings here:
- Make sure you setup monitoring and alerting for your website across a number of different browser configurations. Without SpeedCurve graphs to inspect and investigate, we would still be trying to reproduce the random CORS error in the browser.
- When making a CORS request for fonts, make sure the
vary: Originheader is set.
On point 2, it is worth mentioning that this issue is such a common occurrence it is specifically mentioned in the Fetch specification.
Conclusion
Well that was a lot of investigation work for such a small change, but it just goes to show how difficult it is to debug and fix unknown unknowns. Without fully understanding the detailed ins and outs of caching on a CDN, and how CORS requests for fonts are handled within Chrome, how would a developer ever know that simply adding the vary: Origin header will solve this random error message that occasionally pops up in the browser console.
Post changelog:
- 12/08/20: Initial post published. Thank you to the GOV.UK Notify team developers (Chris, Tom, and David) for their time investigating this issue with me and rolling out the fix. Big thank you to Gaël Métais for spotting the original issue, and Barry Pollard and Andy Davies for answering lots of my questions!
- 13/08/20: Fix a mistake I made around the ACAO header not accepting a wildcard for fonts. Thanks to Eric Lawrence for flagging!